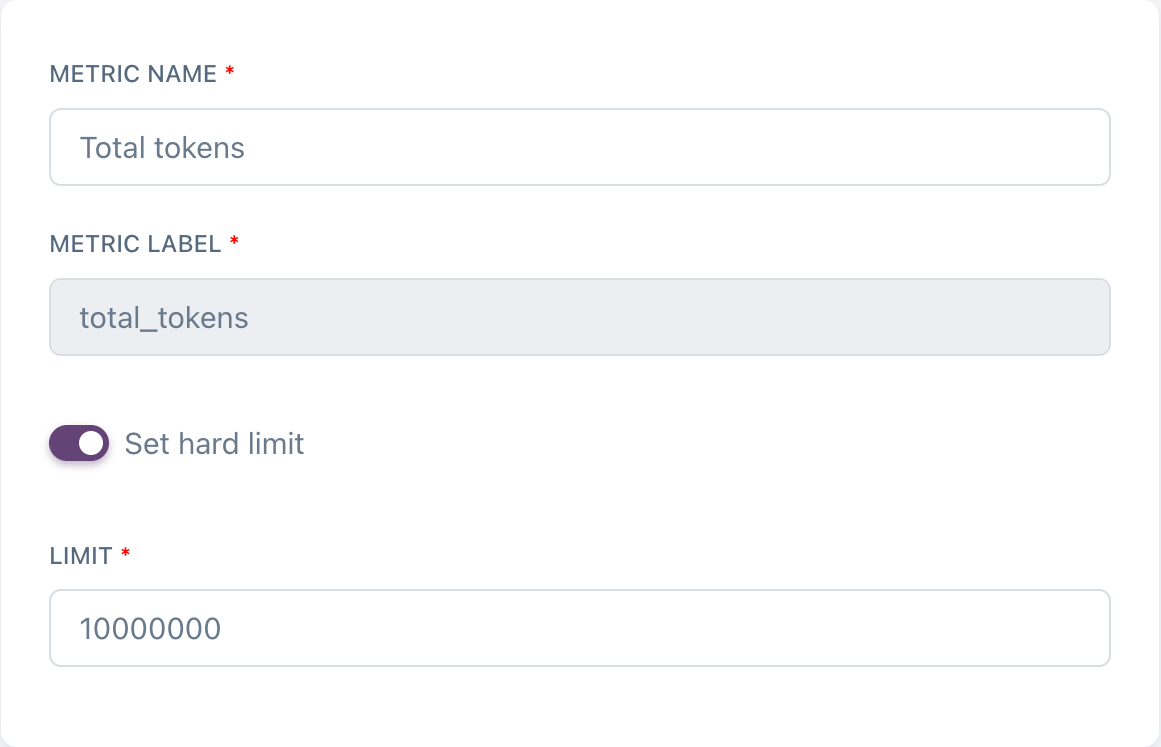
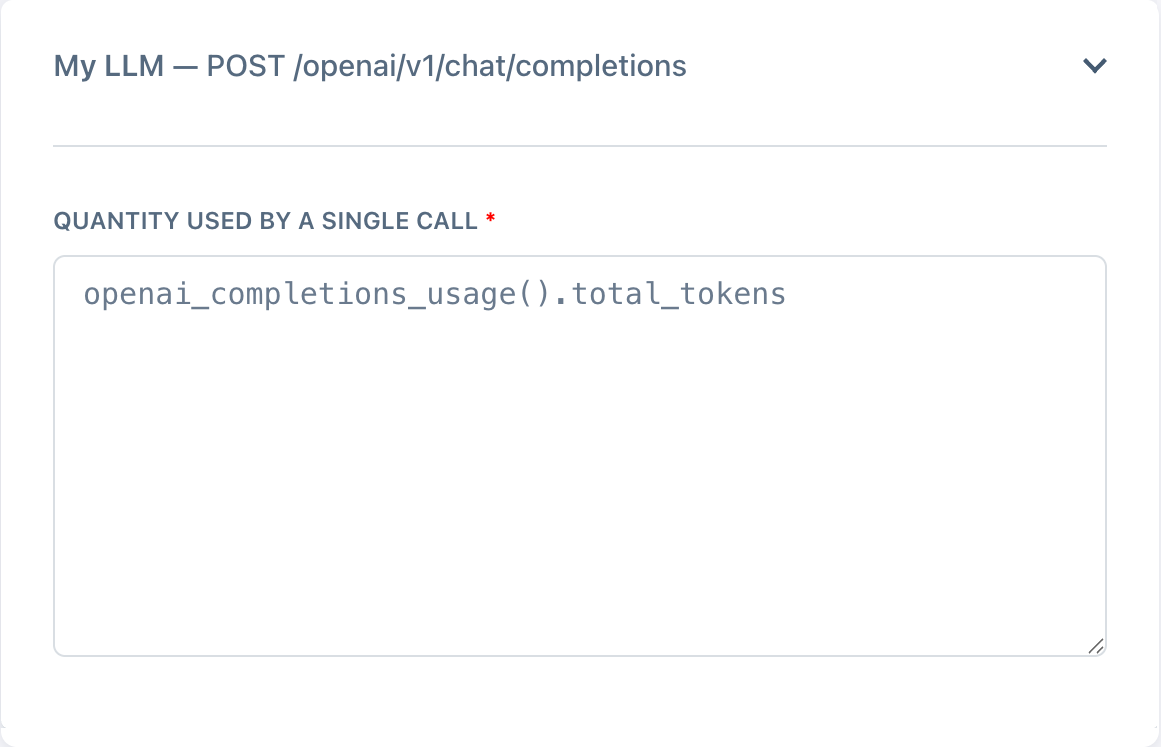
One magic line.
Adding a single line to your Nadles configuration enables automatic LLM token metering. Nadles can meter token usage automatically for many popular streaming response formats — OpenAI Completions API, OpenAI Responses API, Anthropic API, Ollama, Gemini, and more.
Read the docs →